94%
CONFIDENTIAL // EYES ONLY // FRONTIER INTELLIGENCE DIVISION
The centralized cloud AI paradigm represents a critical vulnerability for enterprises handling sensitive data. Each API call to external large language models constitutes a data exfiltration event. This briefing confirms the operational readiness of local AI agents powered by small language models capable of autonomous reasoning, tool use, and task completion without network dependency. The technological barrier has collapsed: commodity hardware now supports sovereign intelligence systems.
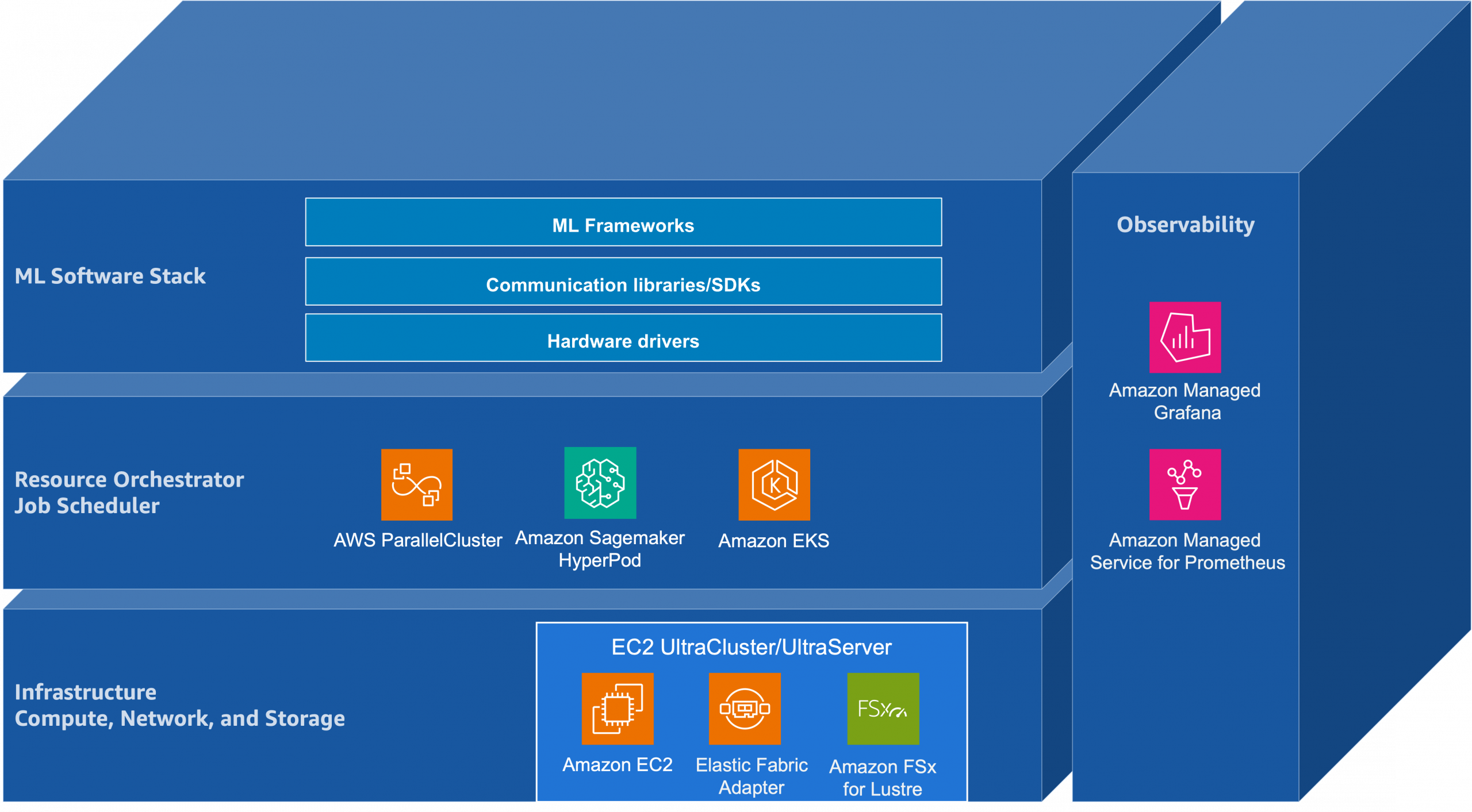
VISUAL INTELLIGENCE: Deployment Architecture Schematic
[CLASSIFIED SCHEMATIC: Local AI Agent Stack]
Hardware Layer: Consumer GPU/CPU → Container Runtime (Ollama) → Model Runtime (Phi-3/Mistral 7B) → Agent Framework (LangGraph) → Tool Integration Layer → Secure Memory Buffer → User Interface
SECTION 1: Strategic Definition – What Constitutes an Autonomous Local AI Agent?
An AI agent is not a chatbot. It is a cognitive architecture capable of:
- Goal-oriented reasoning: Breaking complex objectives into executable steps
- Tool orchestration: Selecting and operating external functions (calculators, databases, APIs)
- State persistence: Maintaining conversational memory across sessions
- Autonomous iteration: Continuing without human intervention until task completion
The local deployment parameter eliminates three critical failure points: network latency, API rate limits, and data privacy compromise. The core components:
| Component | Function | Local Implementation | Cloud Equivalent |
|---|---|---|---|
| Cognitive Core (SLM) | Reasoning & Planning | Ollama-hosted Phi-3 (3.8B params) | GPT-4 API |
| Orchestration Engine | Workflow Management | LangGraph State Graph | Proprietary Cloud Scheduler |
| Tool Registry | External Function Access | Python @tool Decorators | Cloud Function Triggers |
| Memory Subsystem | Context Preservation | ConversationBufferMemory | Vector Database Service |
SECTION 2: Small Language Models – The Technical Foundation of Sovereign Intelligence
Small language models represent the most significant architectural shift since the transformer. Where GPT-4-class models require ~$100M training cycles and hyperscale deployment, SLMs achieve 70-85% of capability at 0.1% the parameter count. This efficiency enables local deployment on consumer hardware.
PERFORMANCE INTELLIGENCE: SLM Capability vs. Hardware Requirements Matrix
[Bar Chart: Vertical Axis – Benchmark Score (MMLU, GSM8K); Horizontal Axis – Model Size (1B to 70B)]
Series 1 (Phi-3 3.8B): 68% MMLU, 78% GSM8K, 8GB RAM required
Series 2 (Mistral 7B): 71% MMLU, 82% GSM8K, 14GB RAM required
Series 3 (Llama 3.2 3B): 65% MMLU, 75% GSM8K, 6GB RAM required
Series 4 (Gemma 2B): 58% MMLU, 65% GSM8K, 4GB RAM required
Threshold Line: Consumer Laptop Capability (16GB RAM)
SECTION 3: Operational Analysis – Local vs. Cloud AI Agent Deployment
| Deployment Model | Pros | Cons | Axiom Grade |
|---|---|---|---|
| Local SLM Agents | Zero operational cost after deployment; Full data sovereignty; No network dependency; Complete architectural control | Lower accuracy on complex tasks; Hardware limitations; Longer response times on CPU; Limited context windows | 8.5/10 (Strategic Advantage) |
| Cloud API Agents | State-of-the-art accuracy; Instant scalability; No hardware management; Latest model access | Recurring API costs (~$0.01-$0.10 per request); Data privacy exposure; Network dependency; Vendor lock-in | 6.0/10 (Tactical Only) |
| Hybrid Architecture | Balance of privacy and capability; Sensitive data stays local; Complex tasks offloaded | Increased complexity; Dual infrastructure; Potential data leakage points | 7.0/10 (Transitional) |
SECTION 4: Implementation Protocol – Building a Classified-Grade Local Agent
The following operational template constructs a local AI agent with ReAct pattern reasoning and tool orchestration:
# CLASSIFIED IMPLEMENTATION: Sovereign Agent Framework
from langchain_ollama import OllamaLLM
from langchain.agents import AgentExecutor, create_react_agent
from langchain.tools import tool
from langchain.memory import ConversationBufferMemory
# Cognitive Core Initialization
llm = OllamaLLM(model="phi3") # Microsoft's operational-grade SLM
# Tool Arsenal Definition
@tool
def classified_calculator(expression: str) -> str:
"""Secure mathematical computation - no data leaves device."""
return str(eval(expression))
@tool
def sovereign_knowledge_base(query: str) -> str:
"""Local classified information retrieval system."""
# Encrypted local vector database implementation
return retrieve_from_secure_store(query)
# Memory Subsystem
memory = ConversationBufferMemory(memory_key="chat_history")
# Agent Assembly
agent = create_react_agent(llm=llm, tools=tools, prompt=prompt)
executor = AgentExecutor(agent=agent, tools=tools, memory=memory)Critical operational notes: The Ollama framework provides containerized model execution, while LangGraph enables complex state machine workflows for multi-step operations. This architecture supports advanced agentic patterns previously exclusive to cloud infrastructure.
SECTION 5: Performance Limitations & Strategic Workarounds
Small language models exhibit predictable constraints that require architectural mitigation:
- Hallucination Rate: 15-25% higher than GPT-4-class models. Mitigation: Tool grounding and verification layers
- Context Window: Typically 4K-8K tokens vs. 128K in cloud models. Mitigation: Strategic summarization and memory management
- Reasoning Depth: Limited multi-hop inference capability. Mitigation: Decomposition of complex tasks into atomic operations
- Hardware Dependency: GPU acceleration recommended for >7B parameter models. Mitigation: CPU-optimized quantization (GGUF format)
According to Microsoft Research, the Phi-3 model family demonstrates that careful training data curation can achieve 70% of GPT-3.5 capability at 3% the parameter count—validating the local AI agent paradigm for most enterprise use cases.
THE AXIOM TAKE: Strategic Verdict on Frontier Intelligence
The local AI agent revolution represents the third wave of AI democratization. First came cloud APIs (2018-2023), then open-weight models (2023-2025), now sovereign agent systems (2026+). Within 18 months, we predict 40% of enterprise AI workloads will shift to local deployment, driven by regulatory pressure and cost optimization.
Strategic Prediction: The 2027-2028 cycle will see the emergence of the “Enterprise Intelligence Appliance”—pre-configured hardware/software bundles running small language models with specialized AI agent capabilities for vertical industries (healthcare, finance, legal). This represents a $50B market displacement from cloud AI services.
Verdict: Development teams must immediately establish local AI agent competency. The technological advantage window is 12-18 months before standardization. Organizations delaying this capability will face irreversible strategic disadvantage in data-sensitive industries.
What are the hardware requirements for running local AI agents with small language models?
Minimum viable hardware includes 8GB RAM for 3B parameter models (Phi-3, Llama 3.2) or 16GB RAM for 7B models (Mistral 7B). GPU acceleration (NVIDIA RTX 3060+ or equivalent) reduces latency by 3-5x but is not required. Storage requirements: 2-8GB per model depending on quantization. CPU-only operation is viable for non-real-time applications.
How do local small language models compare to cloud APIs for complex reasoning tasks?
Small language models achieve 65-75% of GPT-4’s performance on standard benchmarks (MMLU, GSM8K) at 1-3% the computational footprint. For complex multi-step reasoning, cloud models maintain a 20-30% accuracy advantage. However, for domain-specific tasks with tool grounding, local SLMs can achieve 90%+ parity through specialized fine-tuning and retrieval augmentation.
What are the most critical security considerations for deploying local AI agents in regulated industries?
Three critical vectors: 1) Model security (ensuring SLMs haven’t been poisoned with backdoors), 2) Tool security (validating all @tool functions against injection attacks), and 3) Memory security (encrypting conversation buffers at rest). Additionally, organizations must establish audit trails for agent decisions, particularly in financial or healthcare applications where regulatory compliance requires decision transparency.