LLMs & Models Certainly Specifically
3 min read
In particular, this process has expanded beyond just initial training. Consequently, it now includes post-training adjustments and complex tasks during actual use. Essentially, this demands a robust and integrated system.
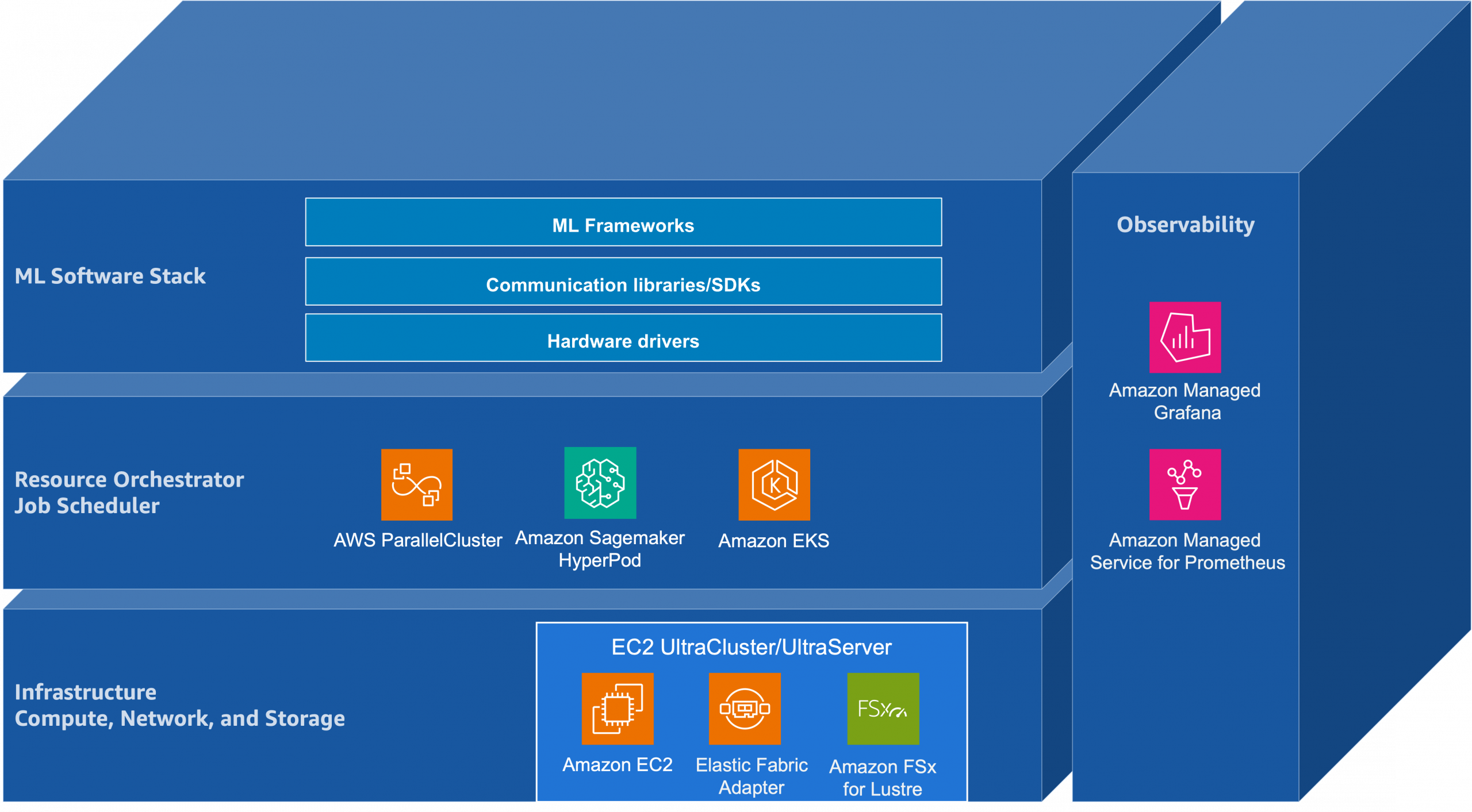
Fundamentally, AWS provides a layered toolkit for this job. Crucially, it includes powerful computing instances, fast networking, and organized storage. Hence, developers can use familiar open-source tools to build and operate these large models efficiently.
| Aspect | Description & Key Components | AWS Services & Tools |
|---|---|---|
| Infrastructure: Compute, Network, Storage |
|
|
| Resource Orchestration: Slurm & Kubernetes |
|
|
AWS Building Blocks for AI
Similarly, foundation models now demand more than just raw compute power for pre-training. Furthermore, post-training and test-time compute have become equally vital scaling paths for everyone. Moreover, AWS provides tightly integrated infrastructure—accelerated GPUs, high-bandwidth networking, and distributed storage—to support people building these systems. Additionally, tools like Slurm and Kubernetes enable efficient resource management at scale. Consequently, observability through Prometheus and Grafana helps teams monitor health, ensuring they can diagnose issues before they disrupt training.
Advancing Scalable AI Infrastructure
“The shift from a single pre-training scaling law to three complementary regimes—pre-training, post-training, and test-time compute—has not fragmented infrastructure requirements; it has reinforced them.”
Ultimately, a complete and efficient foundation model stack on AWS is possible. In conclusion, the architecture combines compute, networking, and storage with open-source tools. Looking ahead, this scalable system supports all model training and inference needs. As a result, the synergy between AWS and OSS enables powerful AI development. Therefore, we can build robust and cost-effective AI solutions together.
Ultimately, foundation models now require integrated infrastructure for training and inference across all scaling regimes. Therefore, AWS provides a cohesive stack of compute, networking, and storage solutions that enable efficient and reliable AI workloads. Consequently, this architecture addresses the growing demands of modern AI development.
In conclusion, the strategic adoption of these building blocks empowers organizations to scale smoothly and innovate faster. Thus, leveraging such ecosystems reduces operational complexity and fosters sustainable progress in AI. Accordingly, this holistic approach is vital for future-ready infrastructure.